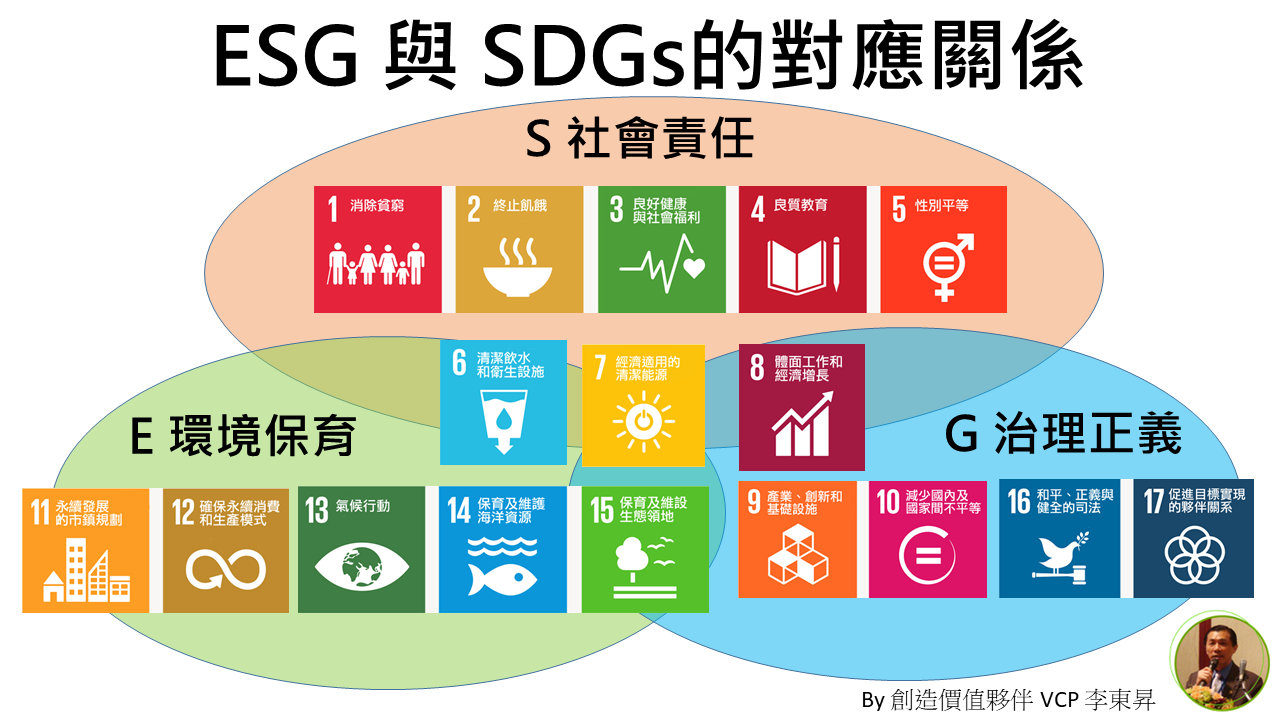
台灣要發展以【全漢字語義】為核心的預訓練模型 HAN-YuYi-PTM之全漢字大語言模型 HANCJK-YuYi-LLM
[李東昇的說明]這是台灣超越中國,成為【漢字文化圈】GAI生成人工智慧的新中心的機會,推出HYGPT-7B,HYGPT-30B模型
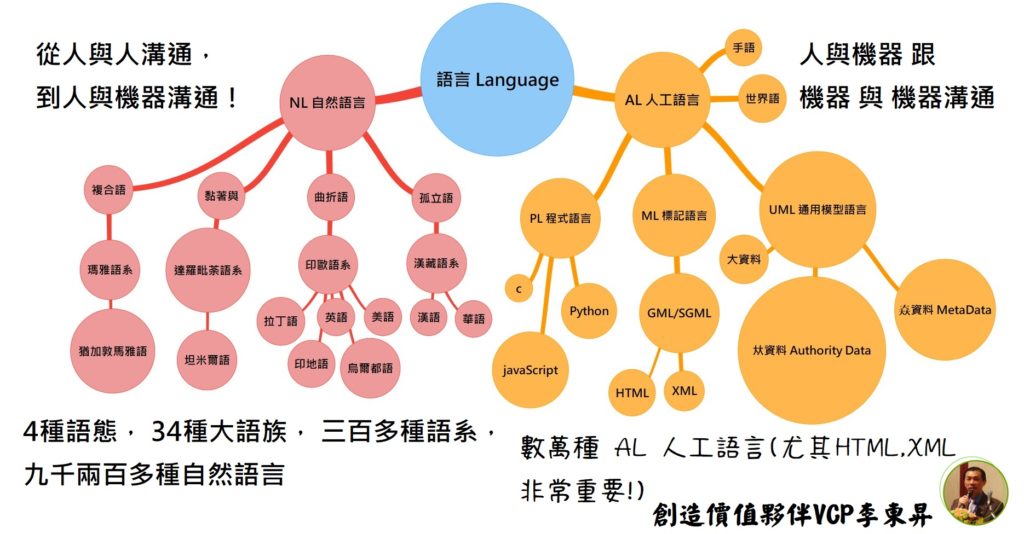
不只是【AI 人工智慧 Artificial Intelligence】還要關注【AL 人工語言 Artificial Language】,而這是進入 WEB 3.0 語義網 的關鍵!
[李東昇的說明]相對於人類智慧(Human) Intelligence 的 AI 人工智慧 開始受到關注,但是 相對於 人類 【NL 自然語言 Natural Language 】的 AL 人工語言 卻沒有受到相對的重視!其實 台灣社會 對於 NL 自然語言 也沒有受到應有的相對重視!
在當今世界上 自然語言有四大語態( 黏著語、複合語、曲折語、孤立語),合計 34腫大語族,三百多種語系,九千兩百多種語言,台灣是 孤立語態中唯一的漢藏語系的完整傳統漢語知識庫,尤其是數位佛典,全漢字字庫(CNS11643),CJK通用漢字的維護者,簡化漢字只有2238個字,而台灣的CNS11643已經收錄超過十萬個漢字(目前超過10萬七千字,正要加入台語、客語、粵語等各種加字跟甲骨文等古字,會超過11到12萬字之間,是全世界最齊全的漢字字典)。
而華語只有1140個發音,但是台語超過3000個發音(三倍於華語),保留完整的漢唐古音!所以 台灣是世界NL自然語言的重要寶庫!
另一方面台灣更是南島語系的發源地之一,是南島語系最分歧最原始的語言庫(台灣的原住民語言),而南島語系包括約1300種語言,分布東西的延伸距離,超過地球圓周的一半,總人口數大約兩億五千萬之多,分布主要位於南太平洋群島,以及臺灣、夏威夷群島、越南南部、菲律賓、馬來群島,東達南太平洋東部的復活節島,西到東非洲外海的馬達加斯加島,南抵紐西蘭。所以台灣是世界南島語系的研究中心,這是台灣另一個非常重要的NL 自然語言的地位。
但是很遺憾的,台灣多數人並不了解台灣在 【NL 自然語言】的重要性。同樣的 台灣在 【AL 人工語言】 的重要性,更糟糕幾乎完全被漠視!
【AL 人工語言】最容易理解的就是 手語 跟 世界語(人造自然語言) ,其實 【UML 通用模型語言 】在台灣完全不被重視,因此對於 模型 跟 資料 的研究,也非常落後!更不要說 UML的翻譯了!所以 完全被中國式的翻譯霸佔,這是台灣最大的痛腳:軟體開發!
至於 【 XML 擴展標記語言 Extensible Markup Language 】跟【HTML 超文字標記語言 HyperText Markup Language】的 來源 SGML 標準通用標記語言 Standard Generalized Markup Language 的 源頭 GML 通用標記語言 Generalized Markup Language 這類的 【ML 標記語言 Markup Language 】 正是構成 WEB 1.0, WEB 2.0 的核心!而 將來 WEB 3.0 的 語義網 的 語義 跟 語意 則是屬於 通用模型語言中的 夶資料 Authority Data 權威資料 , 而 上述的 【ML 標記語言 Markup Language 】 則是 𡘙資料 Metadata 跟 𡘙𡘙資料 Meta Metadata 也就是 模型定義跟模型!
當然還有另外一種就是 【PL 程式語言 Programming Language 】
例如 Python 語言,C語言 跟 Java script 語言等,這就是另外一個重要的關鍵!